

- 一 索引介绍
- 二 索引方法
- 三 索引类型
- 四 聚合索引和辅助索引
- 五 测试索引
- 六 正确使用索引
- 七 组合索引
- 八 注意事项
- 九 查询计划
- 十 慢日志查询
- 十一 大数据量分页优化
索引:

简单的说,相当于图书的目录,可以帮助用户快速的找到需要的内容.
在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。能够大大提高查询效率。特别是当数据量非常大,查询涉及多个表时,使用索引往往能使查询速度加快成千上万倍.
本质:
索引本质:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
1. B+TREE 索引
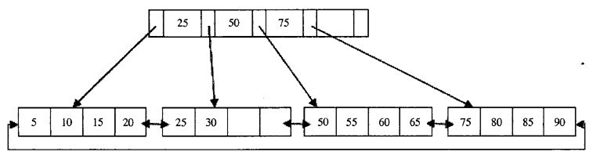
B+树是一种经典的数据结构,由平衡树和二叉查找树结合产生,它是为磁盘或其它直接存取辅助设备而设计的一种平衡查找树,在B+树中,所有的记录节点都是按键值大小顺序存放在同一层的叶节点中,叶节点间用指针相连,构成双向循环链表,非叶节点(根节点、枝节点)只存放键值,不存放实际数据。下面看一个2层B+树的例子:
注意:通常其高度都在2~3层,查询时可以有效减少IO次数。
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一磁盘块中的数据会被一次性读取出来,而不是按需读取。InnoDB 存储引擎使用页作为数据读取单位,页是其磁盘管理的最小单位,默认 page 大小是 16kB。
b+树的查找过程
如图所示,如果要查找数据项30,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定30在28和65之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块由磁盘加载到内存,发生第二次IO,30在28和35之间,锁定当前磁盘块的P1指针,通过指针加载磁盘块到内存,发生第三次IO,同时内存中做二分查找找到30,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
强烈注意: 索引字段要尽量的小,磁盘块可以存储更多的索引.
2. HASH 索引
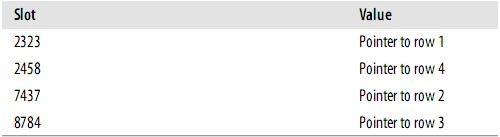
hash就是一种(key=>value)形式的键值对,允许多个key对应相同的value,但不允许一个key对应多个value,为某一列或几列建立hash索引,就会利用这一列或几列的值通过一定的算法计算出一个hash值,对应一行或几行数据. hash索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率.
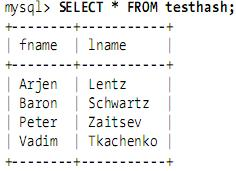
假设索引使用hash函数f( ),如下:
此时,索引的结构大概如下:
3.HASH与BTREE比较:
btree类型的索引:b+树,层数越多,数据量越大,范围查询和随机查询快(innodb默认索引类型)
不同的存储引擎支持的索引类型也不一样
InnoDB 支持事务,支持行级别锁定,支持 Btree、Hash 等索引,不支持Full-text 索引;
MyISAM 不支持事务,支持表级别锁定,支持 Btree、Full-text 等索引,不支持 Hash 索引;
Memory 不支持事务,支持表级别锁定,支持 Btree、Hash 等索引,不支持 Full-text 索引;
NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 Btree、Full-text 等索引;
Archive 不支持事务,支持表级别锁定,不支持 Btree、Hash、Full-text 等索引;
MySQL中常见索引有:
- 普通索引
- 唯一索引
- 主键索引
- 组合索引
1.普通索引
普通索引仅有一个功能:加速查询
2.唯一索引
唯一索引有两个功能:加速查询 和 唯一约束(可含一个null 值)
3.主键索引
主键有两个功能:加速查询 和 唯一约束(不可含null)
注意:一个表中最多只能有一个主键索引
4.组合索引
组合索引是将n个列组合成一个索引
其应用场景为:频繁的同时使用n列来进行查询,如:where n1 = 'alex' and n2 = 666。
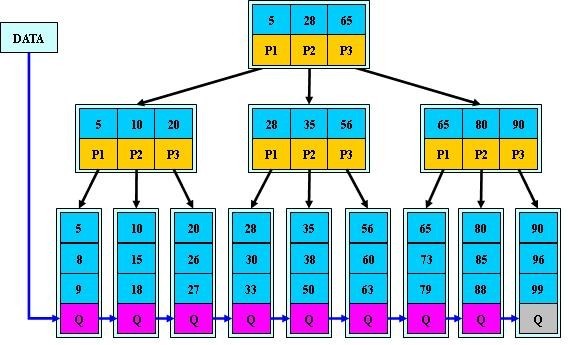
数据库中的B+树索引可以分为聚集索引和辅助索引.
聚集索引:InnoDB表 索引组织表,即表中数据按主键B+树存放,叶子节点直接存放整条数据,每张表只能有一个聚集索引。
如图:
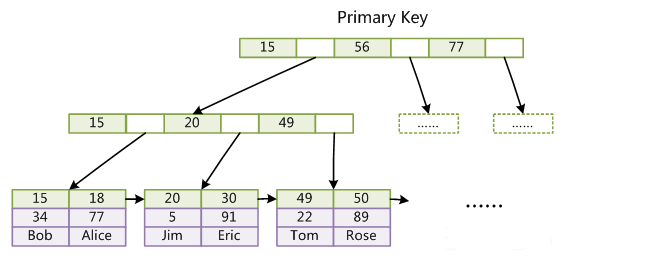
1.当你定义一个主键时,InnnodDB存储引擎则把它当做聚集索引
2.如果你没有定义一个主键,则InnoDB定位到第一个唯一索引,且该索引的所有列值均飞空的,则将其当做聚集索引。
3如果表没有主键或合适的唯一索引INNODB会产生一个隐藏的行ID值6字节的行ID聚集索引,
补充:由于实际的数据页只能按照一颗B+树进行排序,因此每张表只能有一个聚集索引,聚集索引对于主键的排序和范围查找非常有利.
辅助索引:(也称非聚集索引)是指叶节点不包含行的全部数据,叶节点除了包含键值之外,还包含一个书签连接,通过该书签再去找相应的行数据。下图显示了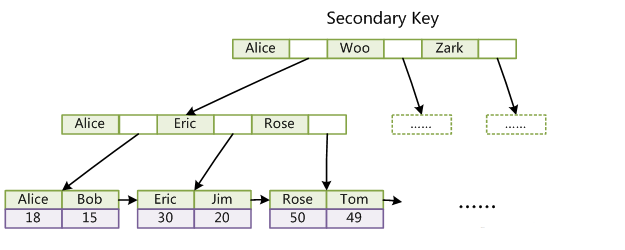
InnoDB存储引擎辅助索引获得数据的查找方式:
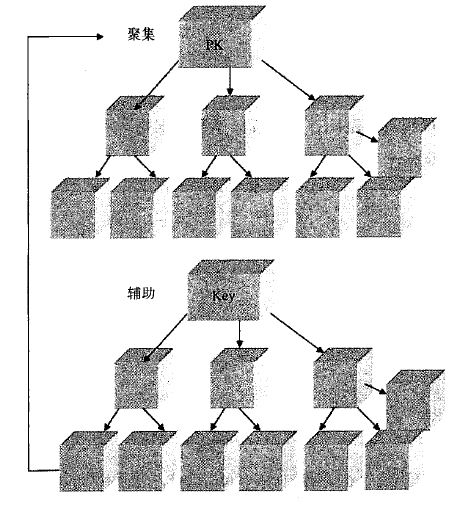
总结二者区别:
相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。
不同的是:聚集索引叶子结点存放的是一整行的信息,而辅助索引叶子结点存放的是单个索引列信息.
何时使用聚集索引或非聚集索引
下面的表总结了何时使用聚集索引或非聚集索引(很重要):
动作描述
使用聚集索引
使用非聚集索引
列经常被分组排序
应
应
返回某范围内的数据
应
不应
一个或极少不同值
不应
不应
频繁更新的列
不应
应
外键列
应
应
主键列
应
应
频繁修改索引列
不应
应
1.创建数据
注意:MYISAM存储引擎 不产生引擎事务,数据插入速度极快,为方便快速插入测试数据,等我们插完数据,再把存储类型修改为InnoDB
2.创建存储过程,插入数据
3.调用存储过程,插入500万条数据

4.此步骤可以忽略。修改引擎为INNODB
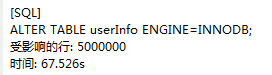
5.测试索引
1. 在没有索引的前提下测试查询速度

注意:无索引情况,mysql根本就不知道id等于4567890的记录在哪里,只能把数据表从头到尾扫描一遍,此时有多少个磁盘块就需要进行多少IO操作,所以查询速度很慢.
2.在表中已经存在大量数据的前提下,为某个字段段建立索引,建立速度会很慢

注意:
1. mysql先去索引表里根据b+树的搜索原理很快搜索到id为4567890的数据,IO大大降低,因而速度明显提升
2. 我们可以去mysql的data目录下找到该表,可以看到添加索引后该表占用的硬盘空间多了
3.如果使用没有添加索引的字段进行条件查询,速度依旧会很慢(如图:)

数据库表中添加索引后确实会让查询速度起飞,但前提必须是正确的使用索引来查询,如果以错误的方式使用,则即使建立索引也会不奏效。即使建立索引,索引也不会生效,例如:
组合索引: 是指对表上的多个列组合起来做一个索引.
组合索引好处:简单的说有两个主要原因:
- "一个顶三个"。建了一个(a,b,c)的组合索引,那么实际等于建了(a),(a,b),(a,b,c)三个索引,因为每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,这可是不小的开销!
- 索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select * from table where a = 1 and b =2 and c = 3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W*10%=100w 条数据,然后再回表从100w条数据中找到符合b=2 and c= 3的数据,然后再排序,再分页;如果是组合索引,通过索引筛选出1000w *10% *10% *10%=1w,然后再排序、分页,哪个更高效,一眼便知
最左匹配原则: 从左往右依次使用生效,如果中间某个索引没有使用,那么断点前面的索引部分起作用,断点后面的索引没有起作用;
explain + 查询SQL - 用于显示SQL执行信息参数,根据参考信息可以进行SQL优化

慢查询日志
将mysql服务器中影响数据库性能的相关SQL语句记录到日志文件,通过对这些特殊的SQL语句分析,改进以达到提高数据库性能的目的。
慢查询日志参数:
查看 MySQL慢日志信息
查看不使用索引参数状态:
查看慢日志显示的方式
测试慢查询日志
执行此段代码:
优化方案:
一. 简单粗暴,就是不允许查看这么靠后的数据,比如百度就是这样的

最多翻到72页就不让你翻了,这种方式就是从业务上解决;
二.在查询下一页时把上一页的行id作为参数传递给客户端程序,然后sql就改成了
这条语句执行也是在毫秒级完成的,id>300w其实就是让mysql直接跳到这里了,不用依次在扫描全面所有的行
如果你的table的主键id是自增的,并且中间没有删除和断点,那么还有一种方式,比如100页的10条数据
三.最后第三种方法:延迟关联
我们在来分析一下这条语句为什么慢,慢在哪里。
你会发现时间缩短了一半;然后我们在拿id分别去取10条数据就行了;
语句就改成这样了:
这三种方法最先考虑第一种 其次第二种,第三种是别无选择