来源:科技伊甸园

公司主营业务为微型电连接器及互连系统相关产品。
(1)连接器业务,公司深耕连接器行业,其产品在手机终端市场份额较大客户逐渐向手机终端的头部企业集中,公司已进入全球主流智能手机品牌供应链,成为华为、中兴、三星、小米等全球知名智能手机企业的供应商,并且已进入闻泰通讯、华勤通讯、龙旗科技等国内知名智能手机设计公司,预计持续受益智能手机市场的马太效应。并且受益5G浪潮,非手机市场的其他智能终端产品也将会有较大的发展:射频BTB产品已出合格产品,并批量用于核心客户,取得了较好的市场反映;汽车连接器及天线的出货量也在不断提升。
(2)精密五金业务,公司正不断通过优化产品流程,提高生产效率,加大自动化力度和水平,提升以设计为核心的工艺加工水平,提高自身的市场竞争力。
(3)软板业务,联合赫比FLEX,扩张FPC软板业务,2019年实现营收3.54亿元,占比16.38%。2020年公司控股子公司恒赫鼎富营收规模持续扩大,稼动率提升,客户结构持续改善,利润水平提升,并且借助赫比Flex成熟的FPC和SMT生产制造技术,布局LCP连接线,产品成熟度不断提高,实现新的利润增长点。
研发构筑技术优势,创新驱动企业成长
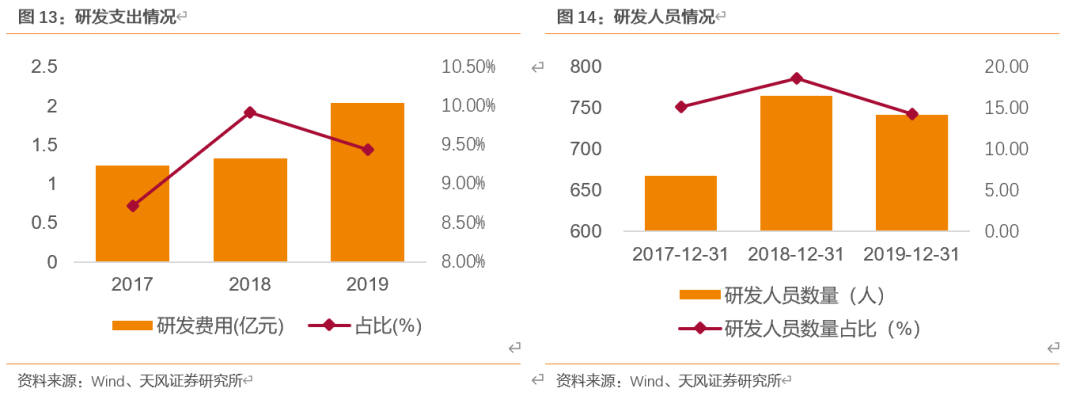
2017-2019年,公司大力支持自主研发,研发费用稳步提升。从研发支出和员工结构方面,都加大了投入和优化。公司研发费用占比由5.52%增加至9.45%,研发人员由668人增长至742人且学历结构得到优化。公司凭借优秀的研发和制造能力,实现了微型射频连接器及线缆连接器组件的技术突破,受益5G浪潮,公司有望占据更大市场。
营收规模扩大,20年毛利率与净利率双增
2014-2019年公司营收规模逐渐增大,实现“翻番”,2020Q1-Q3营收逼近2019全年业绩,归母净利润已超过19年,业绩增厚可期。公司20Q1-Q3毛利率与净利率稳步提升,毛利率分别为26.00%、31.50%、33.81%;净利率为3.59%、11.22%、13.99%,系公司降本增效,各项费用下降,公司盈利能力显著提高。
投资建议:
风险提示:5G发展不及预期;受疫情影响,下游应用需求不及预期;研发进度不及预期
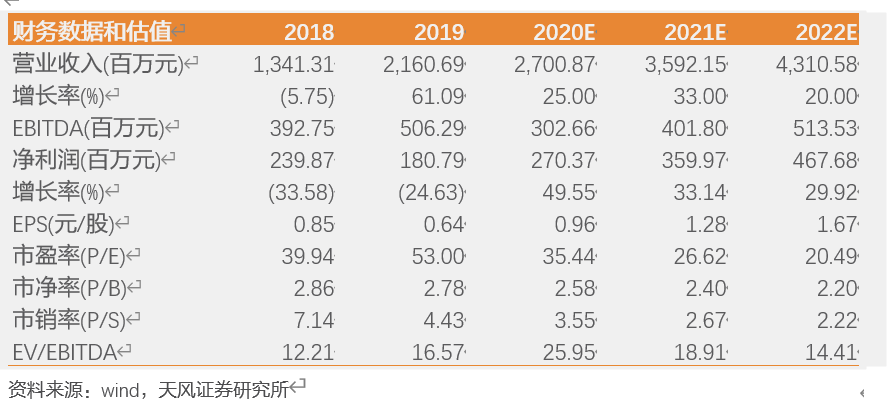

1. 公司介绍
公司创办于2006年,2017年7月A股上市,专业从事微型电子连接器及互连系统相关产品的技术研究、设计、制造和销售服务,具备高可靠、高性能产品的设计、制造能力;公司凭借领先的技术水平,已成为深圳市企业技术中心、深圳市质量强市骨干企业、广东省创新型试点企业和国家级高新技术企业。公司坚持不断开拓创新,成功开发出一系列新产品并成功推向市场,多项产品获得“广东省高新技术产品”称号。
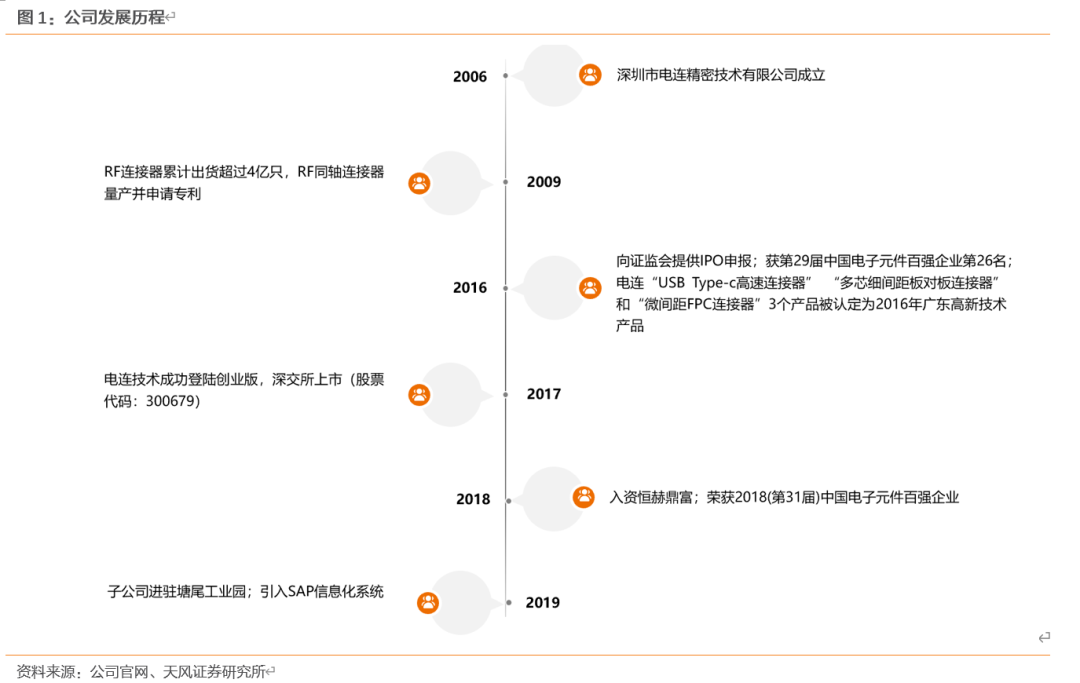
1.1. 股权结构稳定,内生外延实现未来增长
公司实际控制人为陈育宣、林德英夫妇,合计持有公司37.62%的股份。陈育宣先生现任公司董事长、法定代表人。公司第三大股东任俊江为公司创始人之一,现任公司董事,公司控制权稳定。

截至2020年中报,公司共拥有10家子公司,其中上海电连旭晟通信技术为2020新设立子公司。
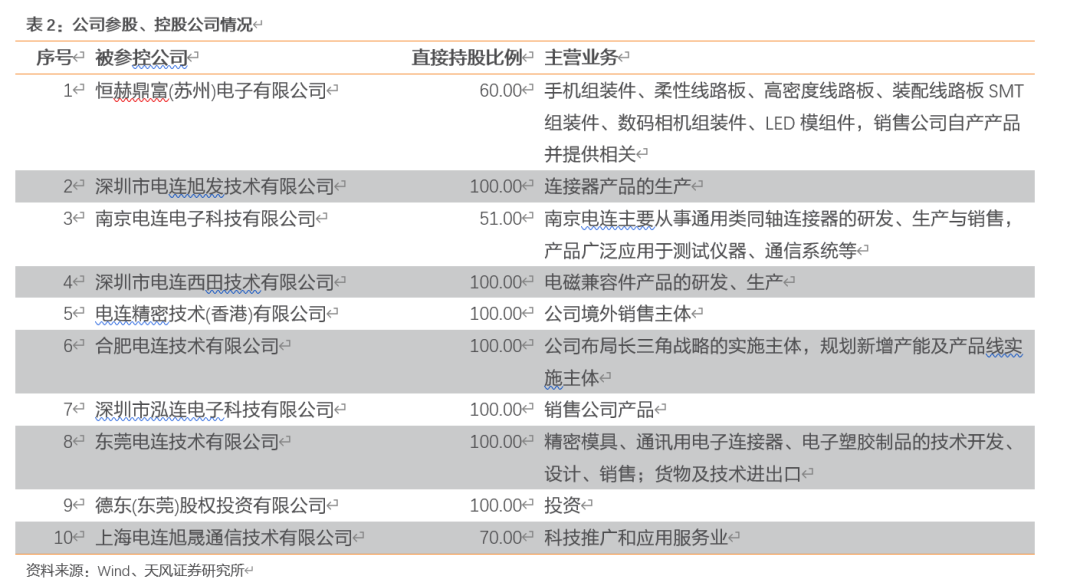
1.2. 公司人员结构呈现专业化,逐步转型技术密集型企业
近三年,公司员工总数由4424人上升至5210人,其中,研发人员由668人上升至742人,占比小幅下滑,由15.10%下降至14.24%,系公司总人数增加。学历方面,近三年公司员工教育水平逐渐提高,公司本科、专科人才实现增长,并且本科与专科人才的占比分别从2017年的2.83%、5.27%增长至2019年的4.64%、8.06%。根据2020年中报,公司已拥有113项国内外专利,其中国内发明专利16项,实用新型专利80项,外观专利17项;境外专利6项,申请14项,相比2019H1,专利数量增加25项。因此我们认为,公司正在逐步实现转型,由劳动密集型企业转向技术密集型。
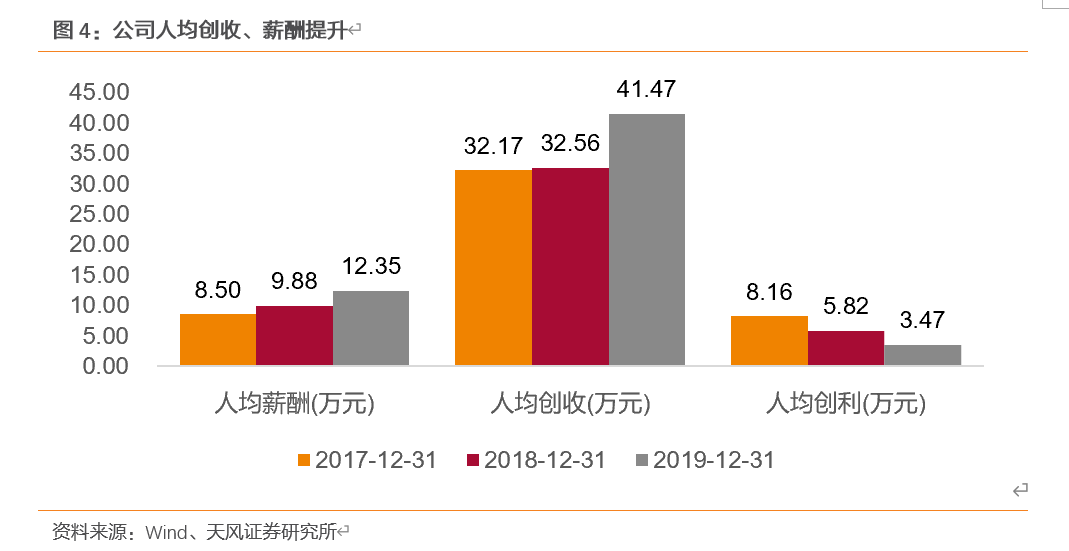
1.3. 营收规模扩大,业绩回暖可期
营收规模扩大,20业绩回暖趋明显。2014-2019年公司营收规模逐渐增大,实现“翻番”,2019年手机行业景气度下滑,公司业务整体平稳增长,主要产品出货量呈增长态势,市占率有所提升,营业收入同比增长61.09%,但受产品价格下降及费用增加等不利因素影响,归母净利润有所下降。2020Q1-Q3营收逼近2019全年业绩,归母净利润已超过19年,业绩增厚可期。
20年为销售毛利率与净利率“由降转增”拐点,业绩可期。2017-2019年毛利率和净利率整体呈下滑趋势,2020Q1-Q3,销售毛利率与净利率实现双增,毛利率分别为26.00%、31.50%、33.81%;净利率为3.59%、11.22%、13.99%。2019年,公司业绩下滑主要系(1)产品价格季节性调价;(2)材料成本及人工成本较去年同期有所增长;(3)研发费用比去年同期显著增加;子公司恒赫鼎富尚处业务拓展期,产能利用率处于持续提升阶段,自动化设备购置更新较多,相应运营成本、费用较高。2020年盈利能力提高系公司降本增效,各项费用下降。
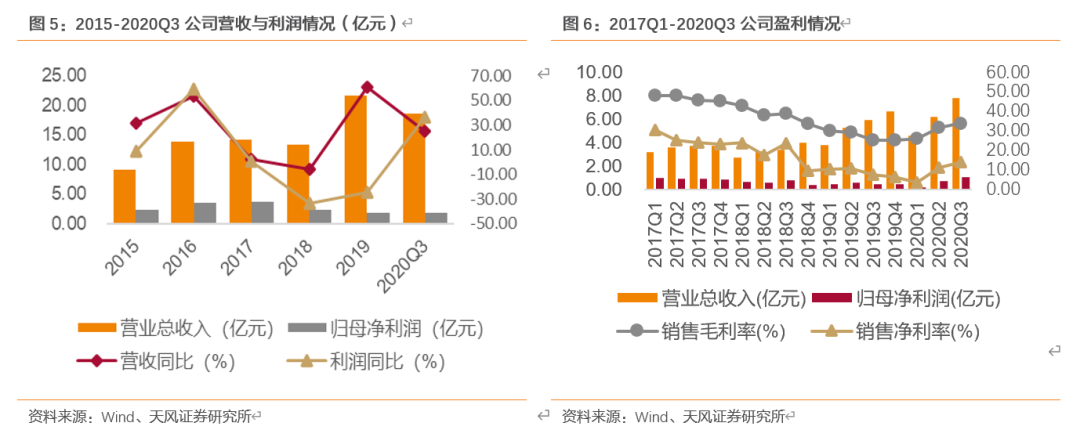
现金流整体表现良好,盈利质量逐年增强。2015-2018年,公司规模扩大,公司经营活动现金净流量皆为正,表明公司运营情况良好。2019年净利润现金比率下滑至0.23,主要因应收项目净增加及存货增加,2020Q3回升至0.73,处于健康水平。同时,公司资产负债率较低,截至2020Q3,资产负债率为19.32%,偿债能力较强。公司通过外延的方式入股恒赫鼎富(苏州)电子有限公司,正式切入FPC产业,借助成熟的FPC和SMT生产制造技术,打造公司未来面向5G的基于LCP/PPS/PI新材料的高频高速传输线,高频射频连接器,毫米波天线产业链,帮助公司加强行业周期性的能力,进一步优化、整合技术资源,不断提高公司的核心竞争力和可持续发展能力。
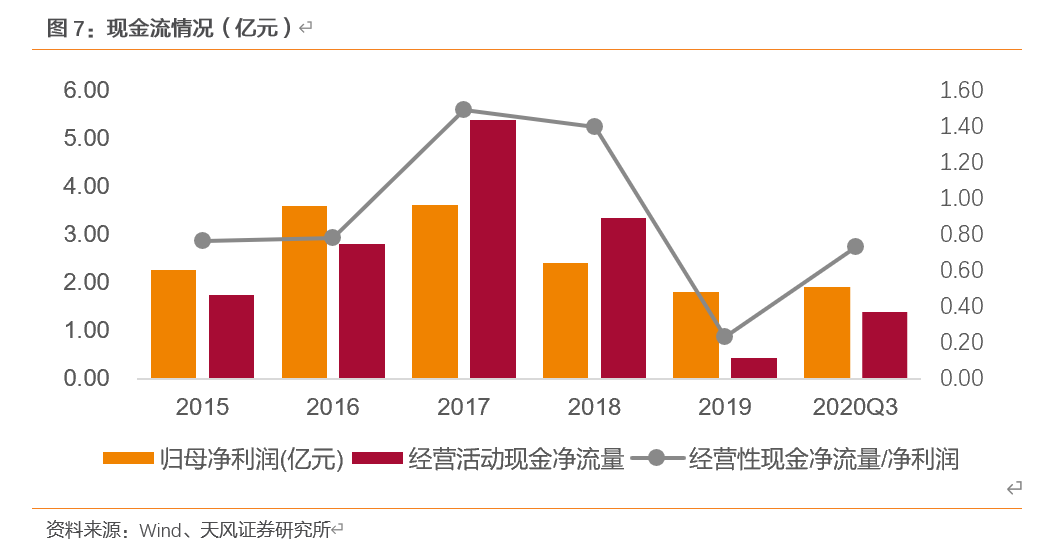
近三年,公司三费合计情况保持稳定,分别为9.21%、9.69%和8.38%,其中管理费用(已剔除研发费用)占比最大,分别为6.47%、7.68%和5.69%。2018年管理费用上升主要因公司员工教育水平和结构实现优化,人均薪酬提高导致管理费用率提升;2019年三费比重下降系营业收入提升,销售费用上升系公司开发新业务营销费用增加且恒赫鼎富首次并表导致。
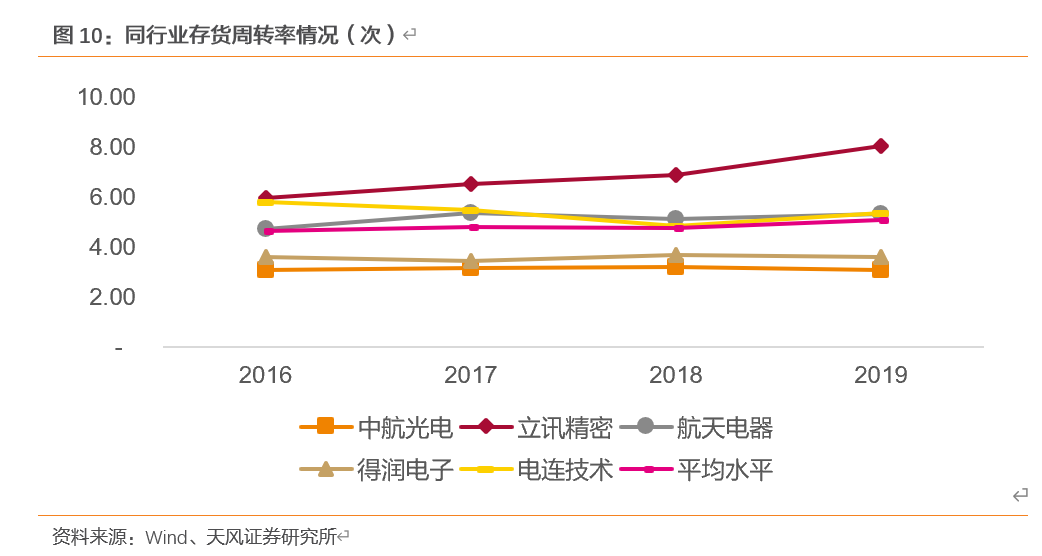
根据公司连接器主营业务,选取同行业公司,我们比较了各公司运营能力指标的情况,结果如下:
2016-2019年,选取公司存货周转率的平均水平为4.63/4.79/4.75/5.08次,公司近四年该指标数据为5.81/5.48/4.84/5.38次,高于同行业知名公司的平均水平。
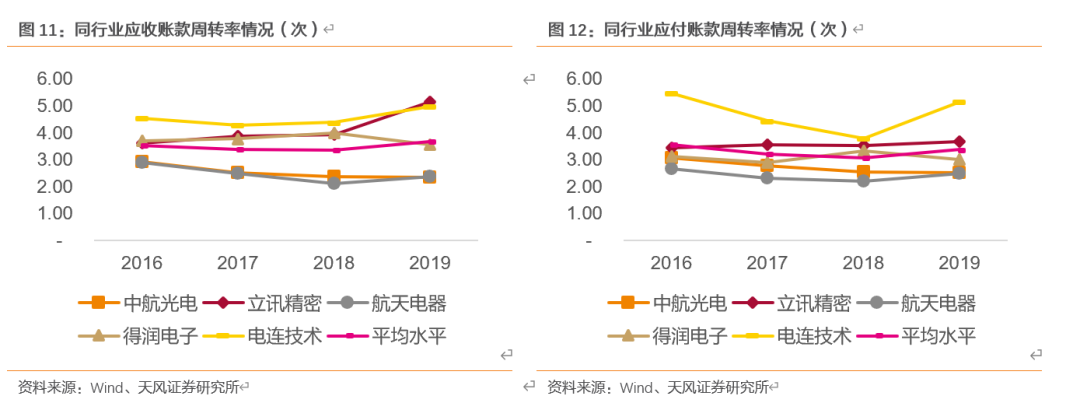
从应收/应付周转率来看,公司对上下游的议价权正在逐步增强。2016-2019年公司应收账款周转率分别为4.54/4.27/4.38/4.98次,对下游客户的收款能力处于可选公司中较高水平;应付账款周转率方面,公司上游原材料主要为金属材料和表面处理服务,公司应付账款周转率整体高于行业平均水平,呈现先降后升趋势,对上游占款能力较弱;2016-2018年,公司应付账款周转率逐年减少,由5.47次下降至3.80次,2019年应付账款周转率有一定程度上升,系收入扩大,营业成本显著上升。
研发构筑技术优势,创新驱动企业成长。2017-2019年,公司大力支持自主研发,研发费用稳步提升。从研发支出和员工结构方面,都加大了投入和优化。公司研发费用占比由5.52%增加至9.45%,研发人员由668人增长至742人。
公司凭借优秀的研发和制造能力,实现了微型射频连接器及线缆连接器组件的技术突破,于2015年、2016年及2017年、2018年、2019连续五年获得中国电子元件行业协会颁发的“中国电子元件百强企业”称号,其中2019年排名第44位。未来,5G毫米波时代,技术难度及复杂度均成倍加大,公司将会合理利用相关研发资源,争取公司的射频类产品能在包括5G通信领域内的一些新的行业和领域有更多的探索及突破。
根据2020年中报,公司已拥有113项国内外专利,其中国内发明专利16项,实用新型专利80项,外观专利17项;境外专利6项,申请14项。公司主要研发项目有15项,多项研发项目都展现了公司对于5G发展的高度重视,并且,同时,公司LCP连接线研发进度顺利,部分项目已经获得客户订单,具体情况如下:

公司设立上海控股子公司,旨在引进面向5G研发的高素质人才,突出前瞻性的布局,瞄准未来5G发展的广阔前景,结合苏州子公司的产业链协同优势,争取在5G的未来竞争中取得较为有利的位置。
2. 业务介绍
公司专业从事微型电连接器及互连系统相关产品的技术研究、设计、制造和销售服务。公司具备高可靠、高性能产品的设计、制造能力,自主研发的微型射频连接器具有显著技术优势,已达到国际一流连接器厂商同等技术水平。
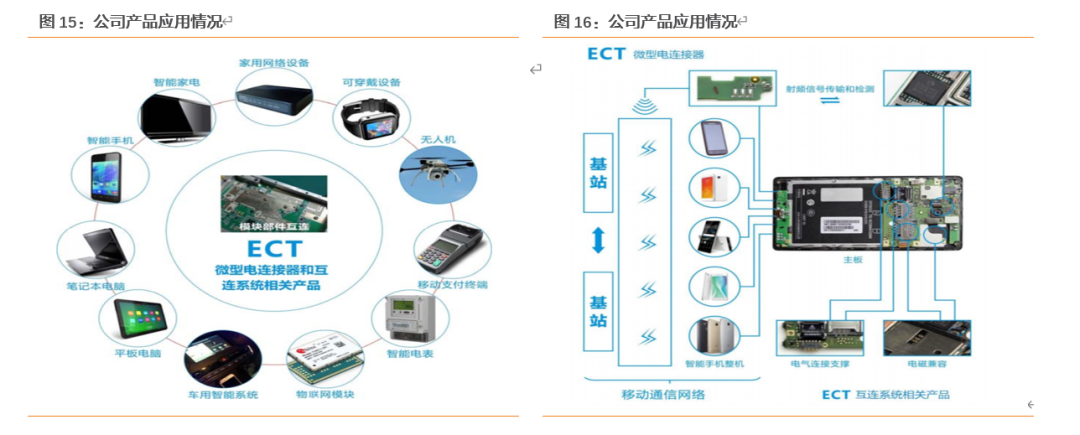
公司经营微型电连接器及互连系统相关产品,其中微型电连接器以微型射频连接器及线缆连接器组件为核心产品,包括微型射频测试连接器、微型射频同轴连接器及射频微同轴线缆组件,是智能手机等智能移动终端产品以及其他新兴智能设备中的关键电子元件;互连系统相关产品主要为电磁兼容件,是智能移动终端产品中起到电气连接、支撑固定或电磁屏蔽作用的元件。
此外公司产品还包括5G天线、卧式/立式射频开关连接器、通用同轴连接器、FPC/BTB连接器、LVDS连接器,MTCC线缆连接器组、汽车用射频连接器、低介电常数材质连接器等其他连接器产品。


公司产品广泛可应用于通讯设备、智能消费电子、数字家电、安防监控、定位导航、自助服务终端、智能水电表、无线数据采集、军工、车载电子、航空航天、医疗等领域。
2.1. 深度合作主流智能手机品牌,受益消费电子景气度上行
品类扩张,多领域贡献营收。2015-2018年,公司营收主要贡献为连接器和电磁兼容件,加总占比超过80%。其他电子元器件近几年占比逐渐增加,2019年末增加至14.90%,该业务主要包含BTB连接器、汽车连接器以及天线和非射频连接器类产品。公司开发出的射频BTB产品已出合格产品,并批量用于核心客户,取得了较好的市场反映;汽车连接器及天线的出货量也在不断提升;非射频连接器类业务方面,公司控股子公司恒赫鼎富(苏州)电子尚处在资本支出投入、规模逐渐扩大,正积极推动申请导入。同时,公司通过外延收购布局柔性线路板,其2019年收入占比16.38%。
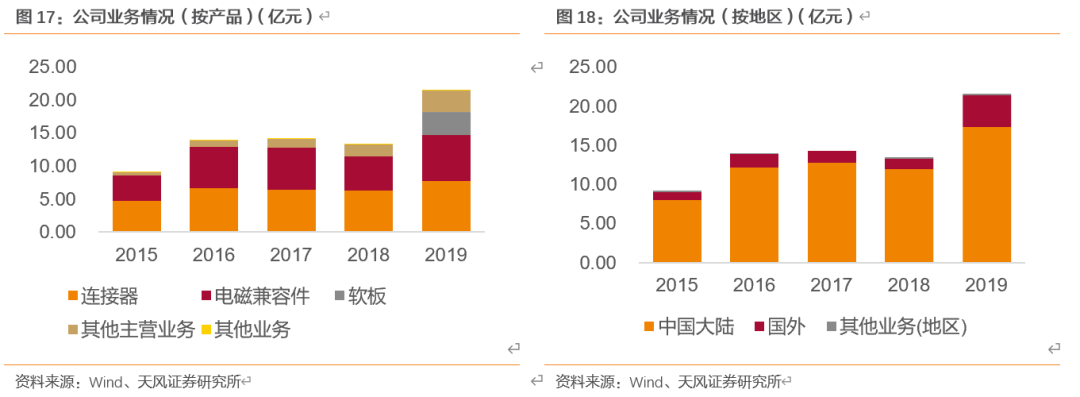
公司的主要客户集中度较高,多为国内手机行业的头部企业。

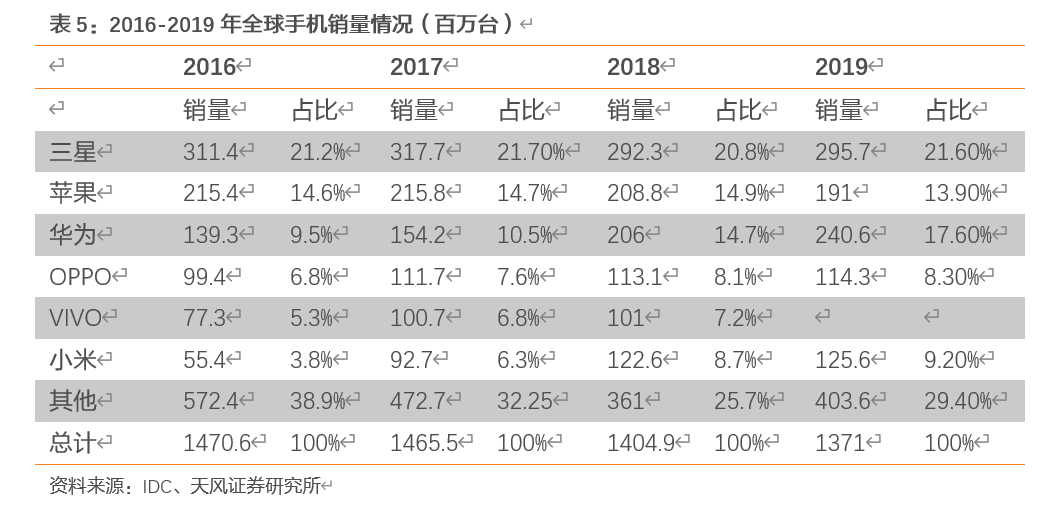
智能手机为连接器主要驱动力,受益全球智能手机集中度提升。公司现有下游手机终端客户为三星、OPPO、VIVO、小米和华为,是世界上主流的手机品牌。根据2016-2019年手机市场销量来看,全球手机市场销售正在往头部集中,前五大手机品牌销量占比为57.40%、61.30%、65.70%和70.60%。公司已经进入全球主流智能手机品牌供应链,成为华为、欧珀、、中兴、三星、小米等全球知名智能手机企业的供应商,并且已进入闻泰通讯、华勤通讯、龙旗科技等国内知名智能手机设计公司。公司作为主流手机品牌的供应商,预计将持续受益智能手机市场的马太效应。
2.2. 5G浪潮推动物联网、工业领域市场扩张
公司在非手机行业的产品品类及成熟度持续提高,出货量取得了一定程度的增长。非手机行业的拓展主要集中在物联网智能移动终端及工业连接器领域,此类产品的市场目前需求量较小,但相对稳定。另外,工业连接器领域公司用户订单持续增长,为进一步拓展工业连接器领域相关业务打下了较好的基础。伴随5G建设推进,非手机市场的智能终端产品预期有较大的市场发展空间。
2.2.1. 汽车电子高歌猛进,业务拓展机遇已现
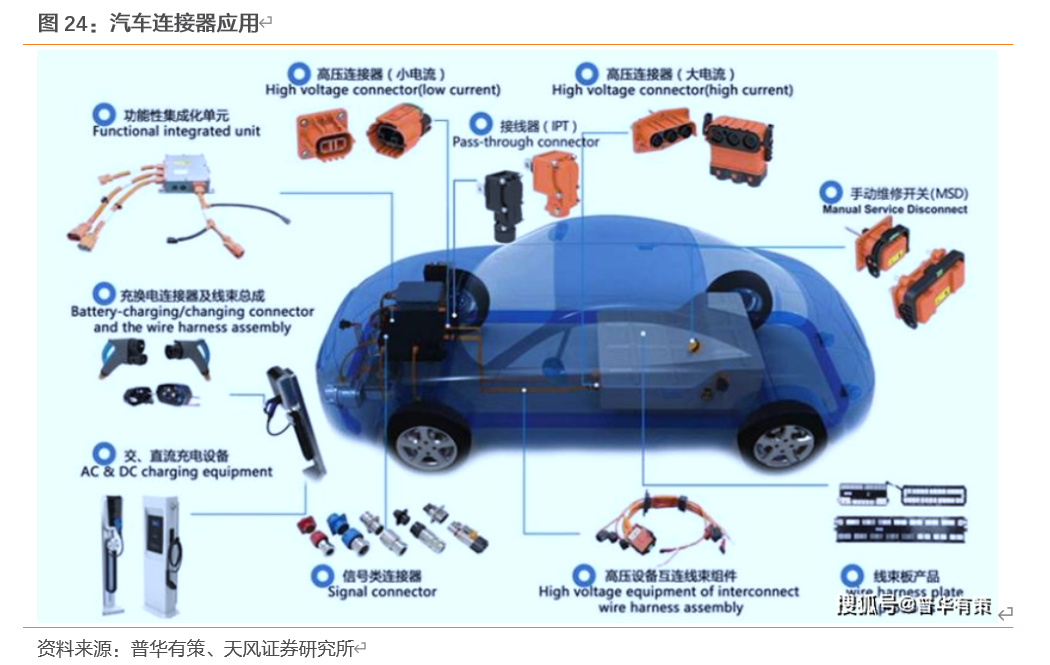
近年来汽车电子高歌猛进,市场规模不断扩大,2007年-2017年,汽车电子成本占整车成本比例从约20%上升至40%左右,2020年达到50%,预计到2030年汽车子产品占整车成本的比例将达到75%以上。随之而来,汽车连接器的市场需求不断增长,在车联网、智慧电动车等潮流推动下,消费者对汽车在安全、娱乐等方面需求增长,衍生出高速传输连接器、车载相机用连接器、车用线束/端子三大市场成长驱动诱因,特别是未来汽车ADAS(自动驾驶辅助系统)整合愈来愈多影像感测模组与镜头,也刺激出更多模组连接器的需求,另外因汽车电子化趋势,车内控制回路日趋复杂,也进一步带动更多车用线束/端子之连接器产品需求,为车用连接器带来更大的市场成长潜力。

自动驾驶需求定义了建造自动驾驶车辆所需的功能、安全级别和整车架构,以及每个连接在架构中需求的实时设置、数据质量及速度要求。因此,每个单一连接的特性可能因连接节点的功能和安全级别而有所不同,可分为车载网络、信息娱乐、安全三类。

可靠数据传输驱动连接器产品变革。可靠的数据传输是无人驾驶必须达到的硬标准,而这一要求的实现需要可靠的汽车连接系统作为支撑,要求在更短的时间内做出决策,以获得更好的安全、可靠和高效结果。在源头生成的任何数据都必须能够迅速、准确无误地到达预期目的地,这一趋势带动了连接器市场的扩大。

汽车连接器产品主要包括HSD连接器、FARKA连接器、高压连接器以及H-MTD连接系统等。HSD连接系统是一种用于低压差分信号的高性能、高屏蔽数据系统,特性阻抗是100Ω,使用屏蔽双绞线。HSD专为汽车市场而设计,可用在如LVDS摄像头、USB和IEEE1394等应用上,可满足多种需求。FAKRA连接器源自罗森伯格,经过二十余年的发展,FAKRA已成为汽车行业通用的标准射频连接器,被业界广泛应用。随着近几年汽车技术的飞速发展,越来越多有助于提高驾驶与乘坐舒适性的智能功能被应用到汽车中,并且经历了从用于高端汽车到标配日常家用级汽车的过程。H-MTD连接器是360°全屏蔽系统,经过试验验证,相较于市场上两点屏蔽的同类型连接器,H-MTD屏蔽衰减性能更优秀,屏蔽效果至少是其它两点屏蔽连接器的1000倍。高压连接器主要使用在新能源汽车高压大电流回路,和导电线缆同时作用,将电池包的能量通过不同的电气回路,输送到整车系统中各部件,如电池包、电机控制器、DCDC转换器、充电机等车身用电单元。
新能源汽车蓬勃发展带来新机会。传统汽车需要用到的电子连接器种类有近百种,单一车型所使用的连接器达到600左右,主要集中应用在发动机管理系统、安全系统、娱乐系统等方面。而相较于传统燃油汽车,新能源汽车电气化程度更高,对连接器的需求量显著增加。传统燃油汽车单车使用低压连接器价值在1,000元左右,而高压连接器的材料成本以及屏蔽、阻燃要求等性能指标高于传统的低压连接器,新能源汽车单车使用连接器价值远高于低压连接器。其中,纯电动乘用车单车使用连接器价值区间为3,000-5,000元,纯电动商用车单车使用连接器价值区间为8,000-10,000元。并且新能源汽车单车使用连接器数量在800到1000个,远高于传统汽车的平均水平。配套充电桩中同样大量使用了连接器产品,且单台新能源汽车充电桩的均价为2万元,而其中连接器的造价大约为3500元,充电桩连接器价值占比较大。
2.2.2. 精密五金持续贡献营收
公司五金类业务主要包括五金弹片和五金屏蔽件,主要应用于消费电子(智能手机,笔记本电脑,平板电脑等),汽车电子通讯,医疗,智能穿戴,智能家居,无人机,设备类等领域。
近三年,公司电磁兼容件业务收入规模不断扩大,公司不断通过优化产品流程,提高生产效率,加大自动化力度和水平,提升以设计为核心的工艺加工水平,提高自身的市场竞争力,利用目前一定的规模优势,努力实现从生产效率提高向市场竞争优势的转化。
2.3. 品类扩张,业务多元化贡献利润增长点
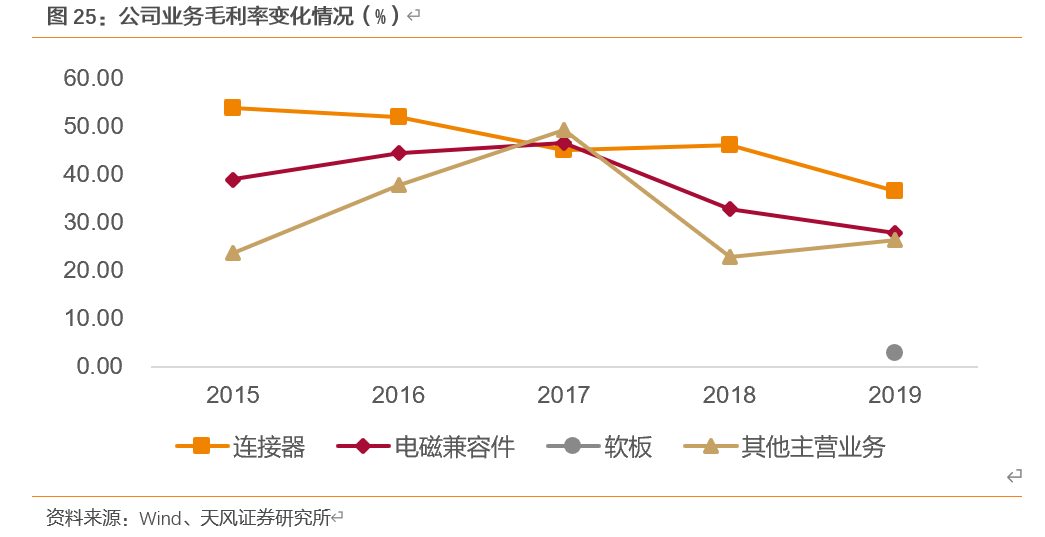
2015-2019年,公司整体毛利率持续下降,由46.14%下降至26.90%,主要因(1)主要产品出现季节性调价(2)规模扩大导致生产体系固定成本有所上升(3)新产品导入,前期研发投入一次性费用较高,导致期间费用增幅同比较大。2020年Q1-Q3毛利情况已经逐渐上升,分别达26.00%、31.50%和33.81%。未来,随着公司研发投入的提升,自动化水平的提高,将从创新、人力成本的角度提高公司盈利水平。同时,公司通过外延方式,拓展了新的产品线,业务的多元性显著增强。
公司在2019年初,成立全资子公司徳东(东莞)股权投资有限公司,并投资入股南京锐码毫米波太赫兹技术研究院有限公司。未来,公司将遵循既定的发展战略,以内生式增长为根基,以外延式并购为跨越,在巩固以射频连接器及互连系统业务为核心的内生增长的同时,利用好资本市场,加大对国内外市场行业的研究和分析,探寻和开拓新的产品和业务领域。
2.3.1. ACES移动出行趋势驱动连接器市场扩大
布局汽车电子,受益行业景气。自动化(A)、互联化(C)、电动化(E)、共享化出行(S)四大趋势将依赖于越来越多的信息,正让数据变成移动出行的燃料。连接器在汽车上的应用体现在汽车控制系统、安全系统、传感器、底盘系统、指示面板,车载电子和娱乐设施等各个方面。公司从2016年左右开始布局汽车射频连接器产品,经历了四年多的摸索及发展,以及汽车行业较长认证周期的考验,随着汽车电子国产化替代的深入,到2020年开始出现了加速发展的趋势,我们认为这一发展趋势将会在未来几年得到延续。目前公司汽车连接器一直在稳定供货,产品主要适用于新能源车及燃油车,并且公司已经能提供一系列汽车电子解决方案:公司已可以量产汽车FAKRA连接器,此外公司的主营业务:微型射频连接器、FPC连接器、数字信号/高速类连接器、线缆和天线等一系列的产品在车载应用、高清防水等汽车领域也有广泛的应用。目前,汽车连接器及天线的出货量也在不断提升,不同领域的应用更为广泛。
国内客户群为主,不断向国际延伸。目前公司的客户是国内靠前的头部自主品牌汽车公司,比如。并且,车企通常倾向于采用本土供应商的连接器,受益中汽车的高速发展,公司有望在中国的汽车电子领域市占率进一步扩大。据2020年中报披露,汽车连接器业务尤其是二季度以来随着整体市场出现环比复苏的态势,因受新冠肺炎疫情影响,主要国外大厂的同类产品销量下降,国产自主品牌汽车及TIER1厂商的相关元件产品的订单实现了较快增长,导致汽车连接器的销售额同比增长较快。
品类质量双升,业务扩展新机遇。目前,公司的汽车连接器产品的品类以及质量均出现了较大的提升,客户群不断扩大。公司已通过ISO/TS-16949:2009汽车行业质量管理体系认证,公司较强的精密制造能力为汽车连接器产品制造提供坚实保证。公司汽车连接器业务领域主要竞争对手为国外厂商,国外厂商凭借技术成熟,产能较高,具备大规模生产能力等优势占据了绝大部分市场份额,因而目前公司尚未完全形成市场规模效应。受海外新冠肺炎疫情蔓延因素和汽车连接器直接竞争对手调整在华策略等因素的影响,公司此类业务拓展可能迎来新机遇。目前,公司的汽车连接器产品经过多年积累已经基本建成了完整的产品类型,随着行业转暖和汽车电子的发展,公司汽车连接器产品在2020年已有了突破和进步。
2.3.2. 5G驱动天线变革,LCP与MPI共存
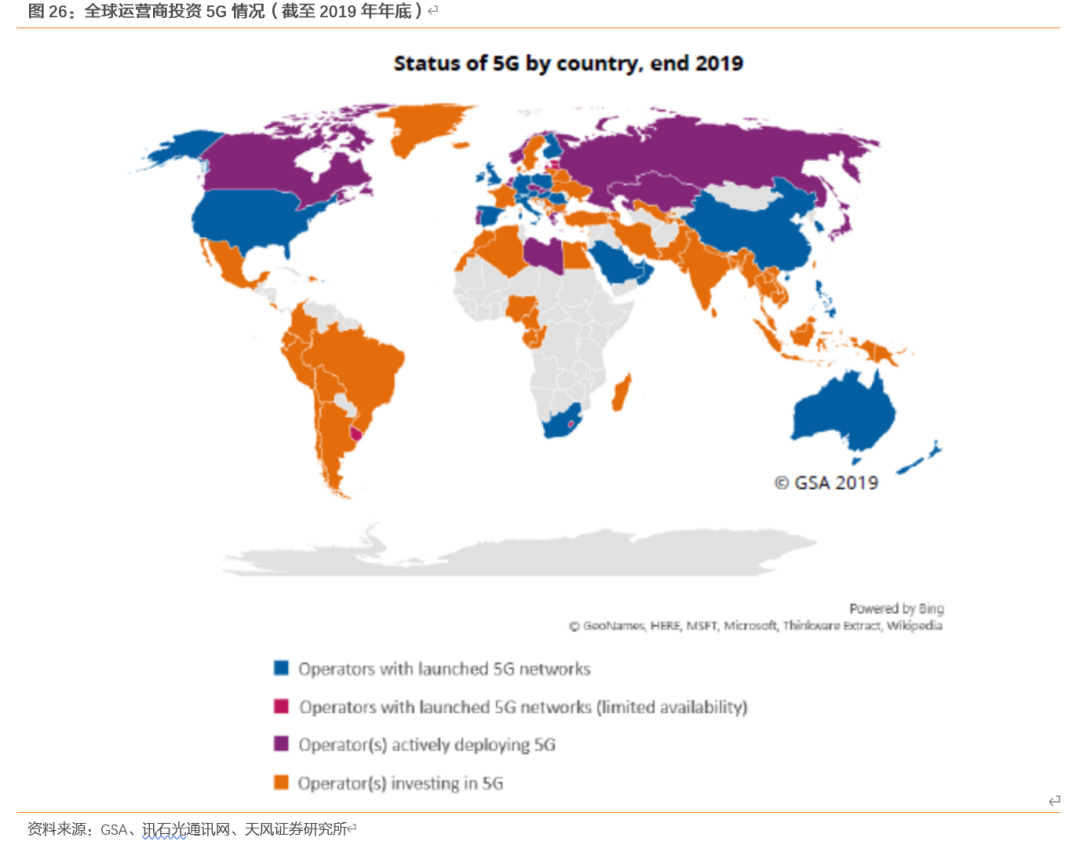
5G投资热潮来临,根据GSA报告,截至2019年底,全球有119个国家/地区的348家运营商正在进行5G投资,其投资的形式包括测试/试用、获得牌照、部署网络和启动服务。77家运营商宣布已在其网络中部署了符合3GPP要求的5G技术。
来自34个国家的61家运营商已推出了一个或多个符合3GPP要求的5G服务。其中,49家启动了符合3GPP要求的5G移动服务(46家全面启动,3家有限可用性启动),34家启动了符合3GPP要求的5G FWA或家庭宽带服务(27家全面启动,7家有限可用性启动)。GSA表示,接近10%的LTE运营商已部署了5G,约8%已经推出了5G服务。
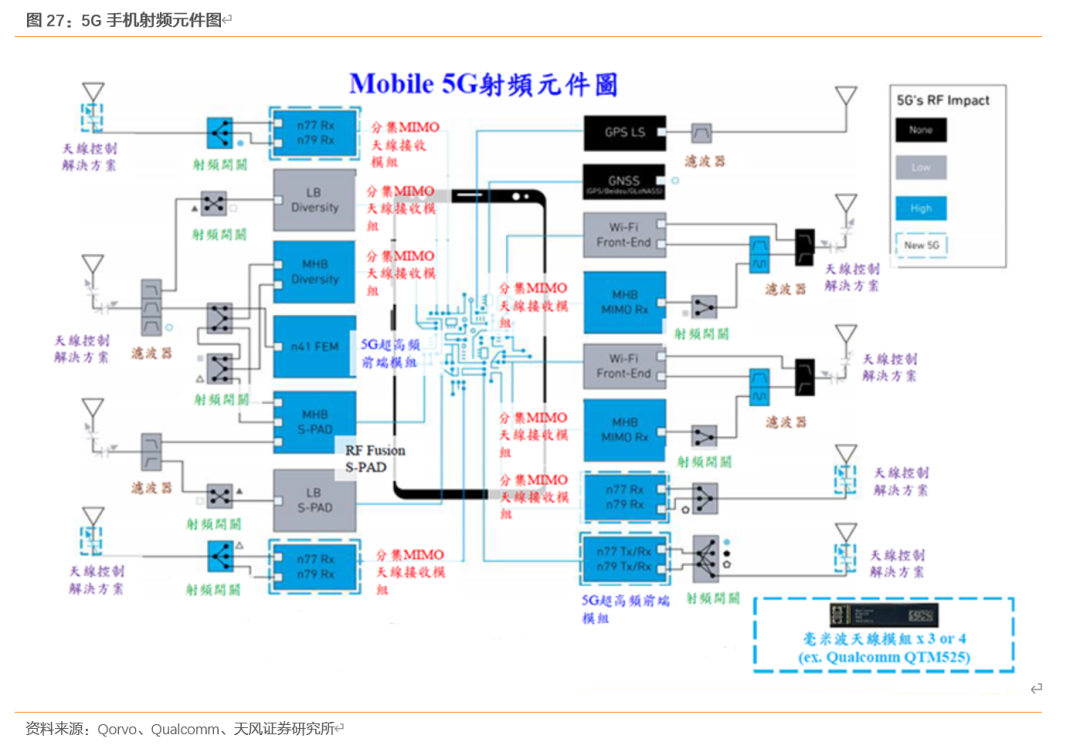
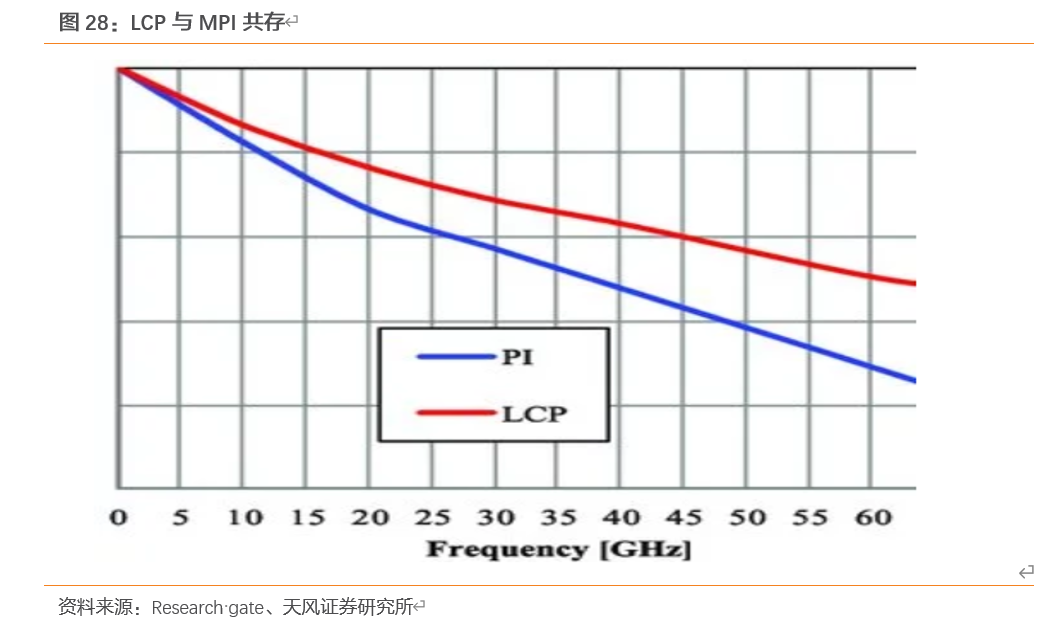
5G驱动电子元器件变革,天线材料朝LCP/MPI发展。在6GHz以下频段,除了支援4G的低频与高频元件之外,还要新增虚线框的5G NR频段元件,从个别元件来看,天线部分,4×4MIMO成为必须,从1T2R提升到2T4R,数量增加(LTE、5G、Wi-Fi、GPS等总计可能11根以上,另有NFC或无线充电);而天线材料则朝向聚醯亚胺(M-PI)与液晶聚合物(LCP)发展,M-PI具低成本优势,可满足sub 6GHz要求,LCP在低介电常数、低损耗与低吸湿性上有更好的表现,但价格昂贵。
液晶聚合物是一种热塑性树脂,其高频特性好,尺寸稳定性好,用于高频多层印制板已深受关注。另外,从其薄膜的基本特性来看,LCP完全有可能有效的弥补PI的缺陷,主要包括低吸湿性、低热膨胀系数、低介电常数及高尺寸稳定性。
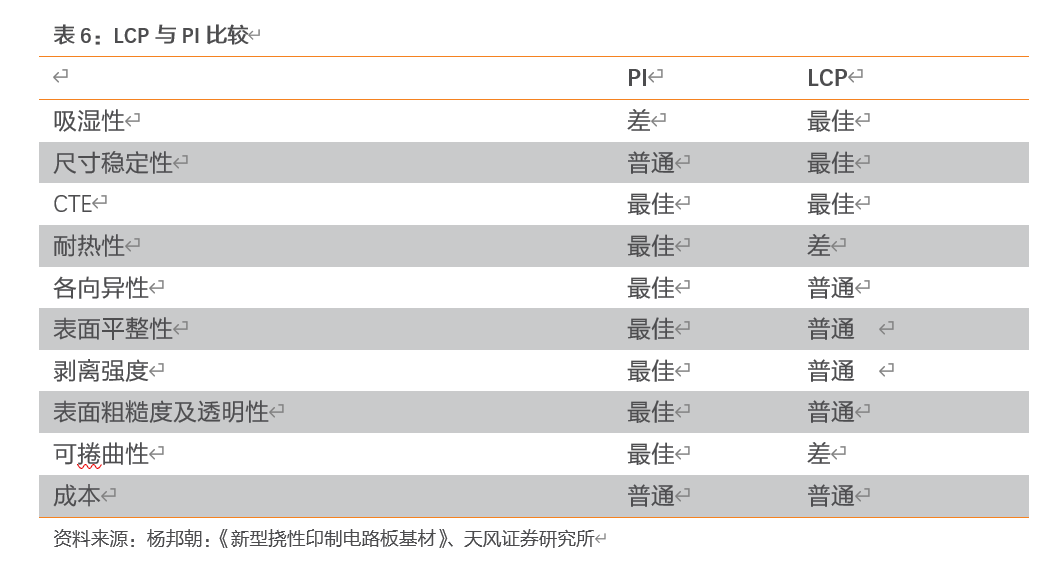
以聚酰亚胺(PI)为基材的FPC天线在10GHz以上的频率中使用会造成信号损耗,并不适合于5G手机。而以LCP为基材的FPC天线具备更低的介电常数和介电损耗,更适合用于高频率通信传输。但由于LCP的结构稳定导致的加工性较低以及供应商数量较少导致LCP薄膜较一般PI薄膜在售价上高出数倍。
针对LCP薄膜的缺点,目前材料厂商提出利用现有PI薄膜材质进行改良的异质性聚亚醯胺(modified-PI)则相当具竞争力,虽然高频性能目前仍不如LCP,但在材料成本、软板制程难度以及供应商上的选择皆较具弹性,若能将传输效率提高到接近LCP薄膜的水准,有机会取代LCP成为普遍采用的材料。由于两种材料各有所长,因此目前供应商会在研发LCP与异质PI两者皆投入资源开发,预期短期内5G天线软板市场会处于多种材料同时竞争的状况。
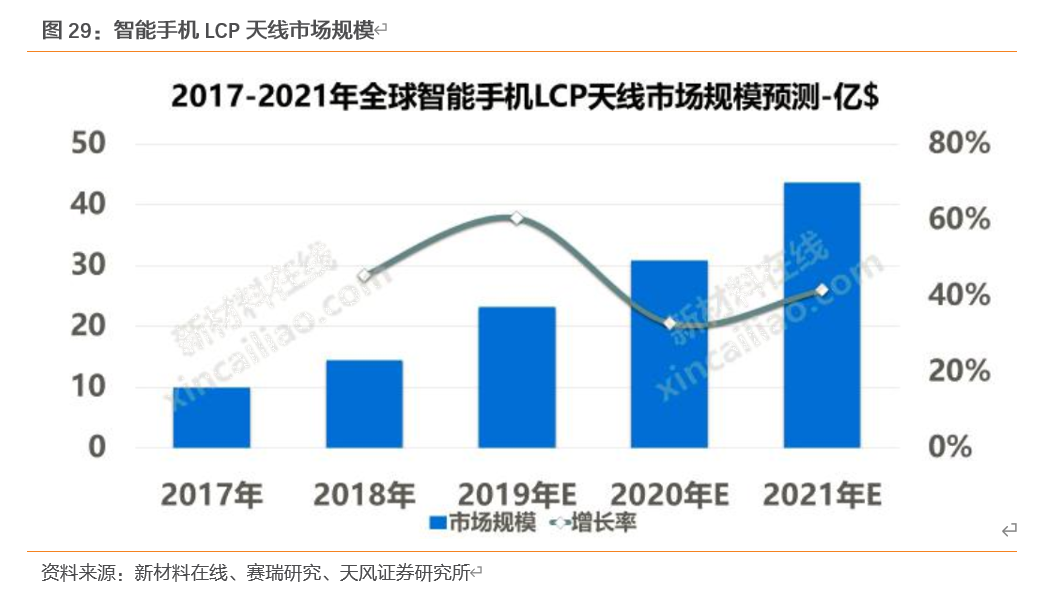
从价值量来看,苹果在其IPHONE X系列产品中已经采用了LCP天线,而2019年iPhone X 中使用的 LCP 天线的单价约为8-10美金,而LDS 天线(基板为塑胶、玻璃等)仅为LCP天线的一半,PI天线仅为0.4美金,可得从PI天线到LCP天线单机价格提升约20倍。
2.3.3. 入股恒赫鼎富,布局LCP连接线
LCP连接线将代替传统同轴连接线,价值量提升显著。Sub 6GHz下,每一路天线信号都需要一路射频传输线传输到射频前端,天线数量的大幅提升带来射频传输线需求增加。传统同轴电缆传输损耗小,可用于高频信号传输,但其体积过大,越来越无法满足终端厂商的设计要求。LCP软板可在仅0.2mm的3层结构中携带多根传输线,在体积减小的同时可以保证极低的传输损耗,有望替代传统同轴电缆成为未来主流方案,给手机内部空间带来更高的利用率。

LCP软板的渗透加速带动BTB(Board to Board)连接器需求也相应增加。BTB连接器主要用来实现PCB的连接或PCB和软板的连接,一般由公头(Plug)和母座(Receptacle)两部分配对使用,其中公头一般焊在FPC排线端,母座焊在板端。受益于5G信号传输方式的变革,BTB连接器有望迎来量价齐升。目前BTB连接器在手机中主要应用于电池、主副板、前后置摄像头、侧键、喇叭、指纹识别等模组,一个手机主板上最小能有5个以上的BTB连接器,并且预计三摄、四摄的设计将令单部手机增加1-3对BTB连接器,同时,5G手机天线数量将从目前2或4根增加到8或16根,令单部手机增加1-2对BTB连接器。

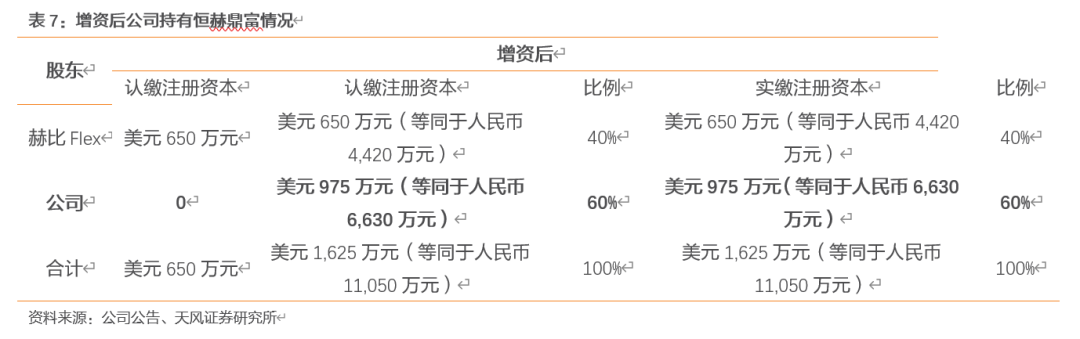
联合赫比FLEX,布局LCP连接线。2018年末,公司增资入股恒赫鼎富(苏州)电子有限公司,增资后公司持有恒赫鼎富60%股权。该公司由赫比(苏州)通讯科技有限公司分立设立,后者拟将柔性线路板业务等相关资产注入,赫比(苏州)由赫比FLEX 100%股权。借助赫比Flex成熟的FPC和SMT生产制造技术,打造公司未来面向5G的基于LCP/PPS/PI新材料的高频高速传输线,高频射频连接器,毫米波天线产业链,帮助进一步优化、整合技术资源,不断提高公司的核心竞争力和可持续发展能力。
赫比Flex是一家成熟的FPC软板生产制造企业,具有多年的FPC加工工艺,技术成熟,工艺领先,为国内外众多优质企业供应商,同时具有较丰富的生产管理经验。由于消费电子行业的快速发展,FPC行业的景气度不断提升,合理布局该行业,可以分享行业发展带来的增量收入及可观的市场空间,丰富公司的产品线,利用公司成熟的客户及市场渠道的经验,不断丰富、提升面向国内外3C行业客户产品组件的供应能力和水平。赫比FLEX系赫比国际有限公司(Hi-P International Limited)全资子公司,公司发展路径与赫比国际相仿,我们认为入股恒赫鼎富(苏州)将有利于公司未来发展路径。

3. 行业概况
连接器在电子系统中是能量和信息交互的界面和通道,随着应用对象、频率、功率、应用环境等不同,有各种不同形式的产品,是电子系统中不可缺少的部件,属于关键电子元件。
3.1. 连接器行业发展概况
3.1.1. 连接器应用广泛,通信及数据传输应用领域发展较快
经过多年发展,连接器应用范围越来越广泛,在各类设备中成为能量、信息稳定流通的桥梁,总体市场规模基本保持了持续增长的态势。连接器的全球市场规模已由1980年的86亿美元增长至2018年的667亿美元,较2017年提升了11%,、自2012年以来年复合增长率约为5%。
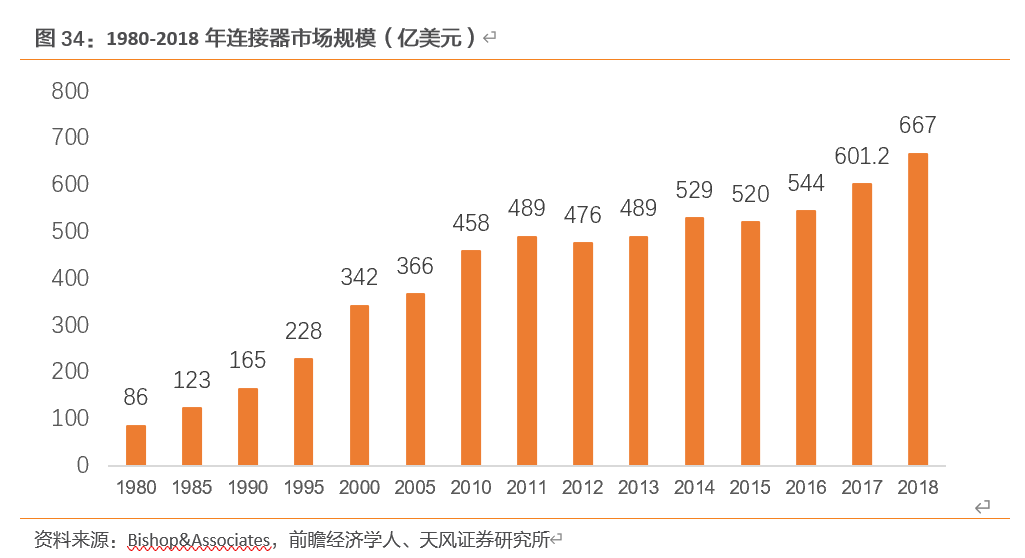
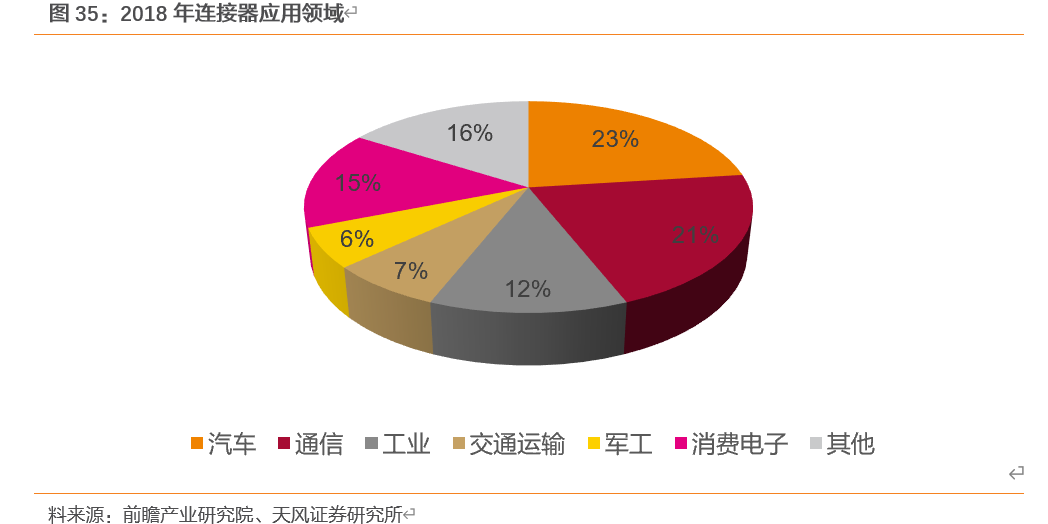
连接器的具体应用领域可划分为汽车、通信、工业、交运、军事及航天航空、消费电子等几大类。从2018年的情况来看,全球连接器市场中,汽车领域所占比重最大,为23%;其次是通信领域、消费电子、工业领域,合计占比达71%。
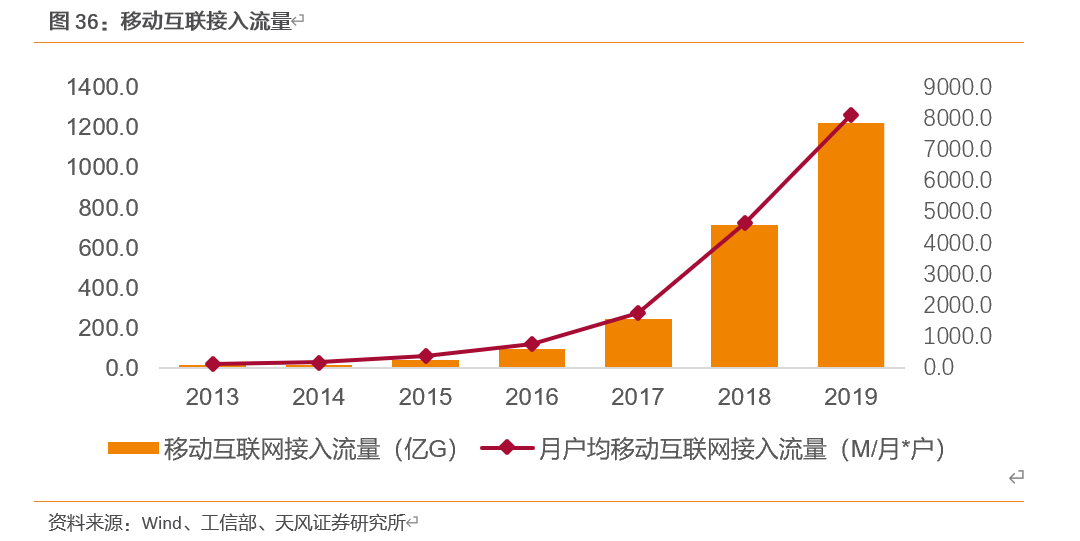
在移动互联网的推动下,通信及数据传输应用发展较快。2012-2014年,通信及数据传输用连接器的市场规模从78.43亿美元增长到107.60亿美元,增长了37.19%,显著高于连接器总体的市场规模增速;在连接器总市场规模中的占比从2012年的16.67%提高到2014年的20.36%,已成为连接器的第二大应用领域。连接器在通信及数据传输上的应用体现在手机、网络设备、无线网络基础设施、电缆设备等方面,连接器在这一应用领域的快速增长和全球移动互联网的迅速发展紧密相关。以中国为例,移动互联网年接入流量从2013年的13.2亿G增长到2019年的1220亿G,年均复合增长率达到121.91%;月户均移动互联网接入流量从2013年的122.3M/月·户增长到2019年的8125.9M/月·户,年均复合增长率达到106.91%。移动互联网的迅猛增长态势促进了网络设备和移动终端市场的持续扩大,使得通信及数据传输用连接器获得了快速的发展。
未来几年,全球移动互联网将在移动医疗、新能源汽车等新兴产业的推动下保持快速发展势头,智能手机等智能移动终端产品的市场在更新换代中仍将保持繁荣状态,可穿戴设备等新兴产品渗透率将快速提高,因此通信及数据传输市场仍能够保持较快的增长速度。
电脑及外设应用波动较大,新技术成为增长点。电脑及外设用连接器的市场规模在2012年为94.35亿美元,在2013年大幅下降到78.92亿美元,2014年有所恢复,但距离2012年的水平仍有一定差距。近年来,全球台式机、笔记本电脑销量增长不稳定,同时新产品的单机使用接口数量随着笔记本电脑的超薄化、无线化趋势有所减少,造成了电脑及外设用连接器总体市场规模的较大波动。未来随着Type-C高速连接器的逐步推广,相关新产品将拥有较大的增长空间。
汽车是连接器第一大应用领域,新能源化和智能化助力增长。2012-2014年,汽车用连接器的市场规模从101.79亿美元增长到117.30亿美元,略高于连接器总市场规模的增速,是连接器的第一大应用领域。连接器在汽车上的应用体现在汽车控制系统、安全系统、传感器、底盘系统、指示面板,车载电子和娱乐设施等方面。全球汽车工业正处在新能源化和智能化的浪潮当中,以智能电动汽车为代表的新一代汽车产品在动力、控制、传感、安全等系统中使用了更多的电子零部件,对连接器的数量需求和质量需求显著增长,这将推动汽车用连接器市场在高基数水平上持续发展。
3.1.2 国内制造业带动连接器市场规模持续扩大
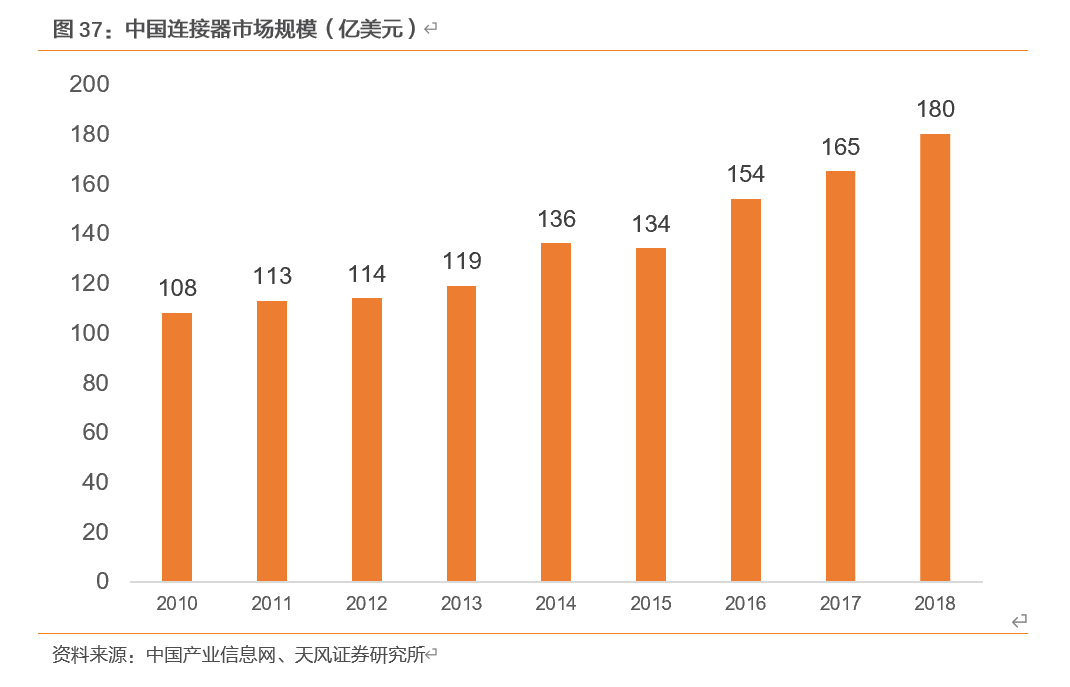
近年来,随着国内工业化、信息化、城镇化同步推进和内需潜力不断释放,国内制造业获得了广阔的发展空间,实现了量与质的双重发展。中国在制造业规模已跃居世界第一位的同时,通过持续的技术创新大大提高了制造业的综合竞争力,不但在一批重大技术装备取得了突破,更在一些新兴产业中获得了较大的影响力,其中最具代表性之一的是智能手机产业。国内制造业向着更广、更深发展,扩大了广泛应用在各种产品和设备中的连接器的国内市场规模。2010-2018年,中国连接器市场规模由108亿美元增长至180亿美元,年均复合增长率为6.59%。
国内连接器的庞大市场,推动了本土连接器企业的快速发展。目前,在多个应用领域中,已涌现出一些技术水平高、自主研发能力强、资金规模雄厚、拥有自主品牌的本土企业:

3.2.市场供求状况及变化趋势
目前,连接器的主要下游之一是市场庞大、产品繁多的3C产业。许多智能手机采用射频同轴连接方式作为将射频信号传递到天线模块的解决方案,带动了微型射频连接器及线缆连接器组件的快速发展。
连接器的重要下游中,智能手机、平板电脑和汽车的市场规模较大,同时技术发展较快,近年来产品迭代加速,因此连接器的需求情况受这些行业的影响较大:
3.2.1 智能手机
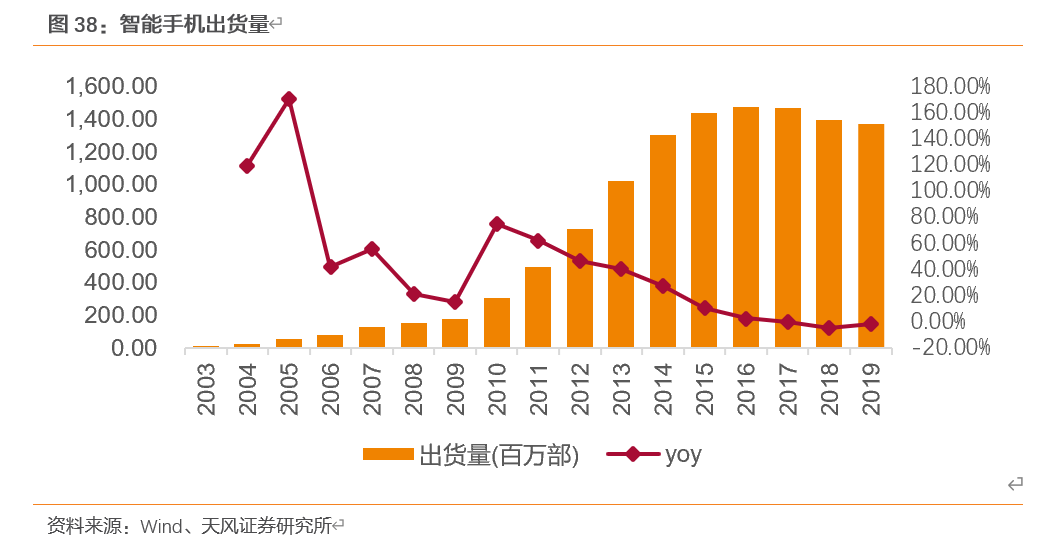
近年来,全球智能手机市场景气度有所下滑,首次出现负增长。2013-2019年全球智能手机出货量由10.2亿部增长至13.71亿部。随着出货量基数增长到较高水平,智能手机出货量的相对增速将有所放缓,从2017年开始出现负增长。
3.2.2. PC及平板电脑
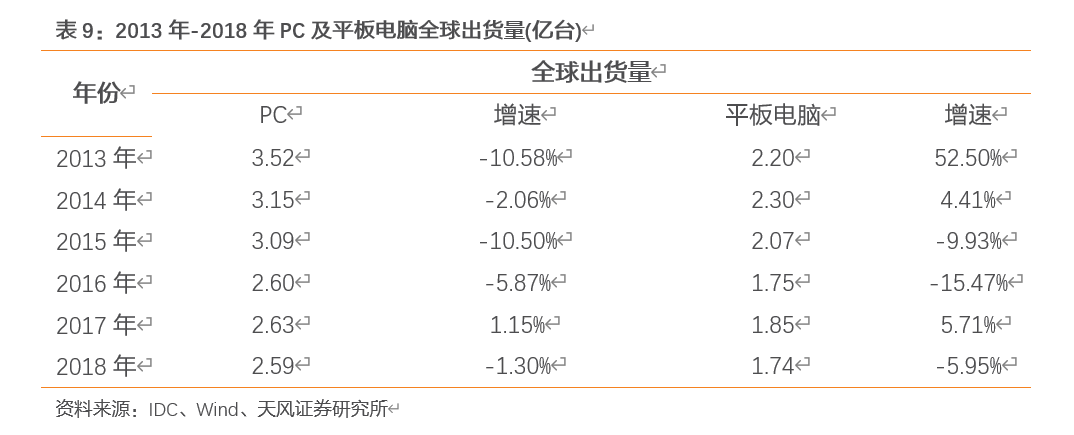
在移动智能终端的冲击下,国际PC产量持续萎缩,而平板电脑产量也经历了较大波动。2013-2018年,PC产量从3.52亿台下降到2.59亿台,平板电脑产量则依年为2.20亿台、2.30亿台、2.07亿台、1.75亿台、1.85亿台和1.74亿台。PC和平板电脑市场相关厂家因此也加速发展“二合一”式笔记本电脑的步伐。
3.2.3. 汽车
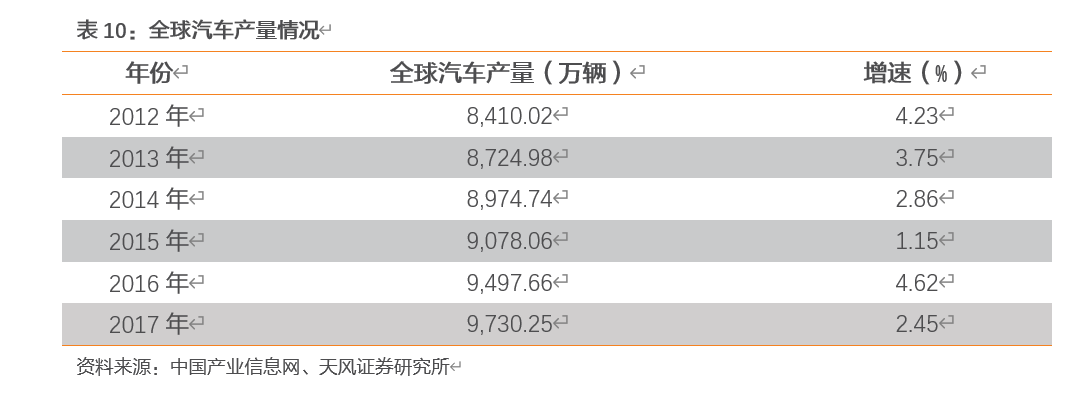
在中国汽车市场持续繁荣的拉动下,全球汽车产量实现了稳步增长。2012-2017年全球产量由8,410.02万辆增长至9,030.25万辆,年均复合增长率分别为1.43%。目前中国等发展中国家人均汽车拥有量与发达国家相比仍存在较大差距,因此未来全球汽车市场仍存在广阔的发展空间。预计2020年全球汽车产量将超过1.1亿辆,其中中国汽车产量则将达到3,000万辆。
在汽车市场总体增量持续增长的大背景下,新能源化和智能化的趋势将推动汽车产品进行全面的更新换代。以中国为例,2012年7月国务院印发《节能与新能源汽车产业发展规划(2012-2020年)》,对国内纯电动汽车和插电式混合动力汽车的累计产销量提出了2015年达到50万辆、2020年达到200万辆、累积产销500万辆的目标;2015年5月,国务院在《中国制造2025》中,提出了“继续支持电动汽车、燃料电池汽车发展,掌握汽车低碳化、信息化、智能化核心技术”。科技含量更高、需要更多连接器的新能源汽车、智能汽车正在迎来快速发展的时期。
综上所述,未来连接器的下游产品市场总规模将保持增长,对连接器形成强劲的需求,连接器行业将得到进一步发展。
3.3. 竞争对手
国外企业在我国高端连接器市场占据主导地位,但国内外技术与规模差距趋于收敛,实力较强的本土企业初具影响力。
——我国连接器市场依然被国外企业占据较大份额。全球市场中,泰科电子与安费诺两大国际连接器巨头占据较大份额,占比分别为16%和11%,富士康和两家中国企业全球市场排名前10,占比分别为5%和3%;而国内市场中,泰科与安费诺等国外企业依然占据较大份额,国内仅富士康、立讯精密和三家企业市场份额排名前10。
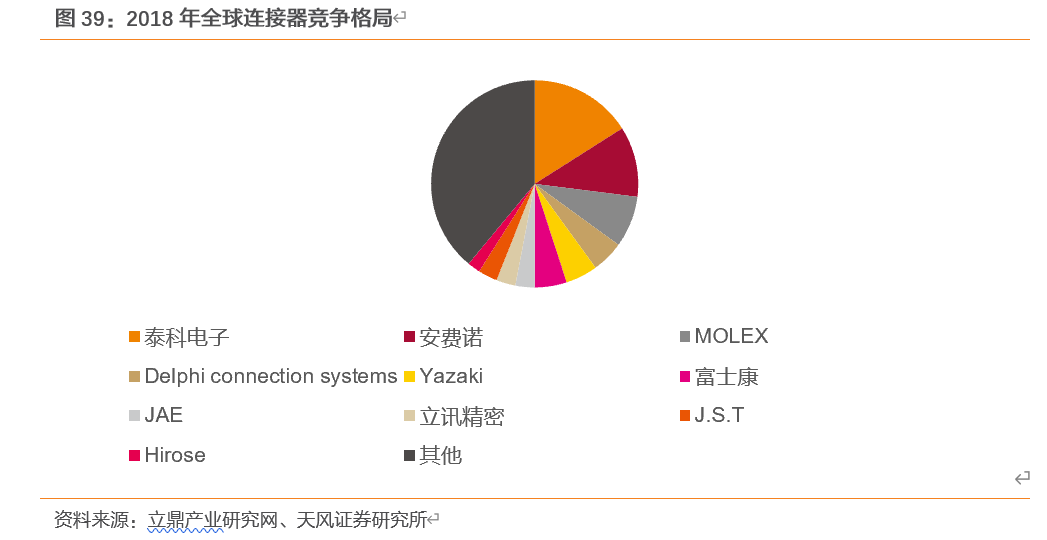
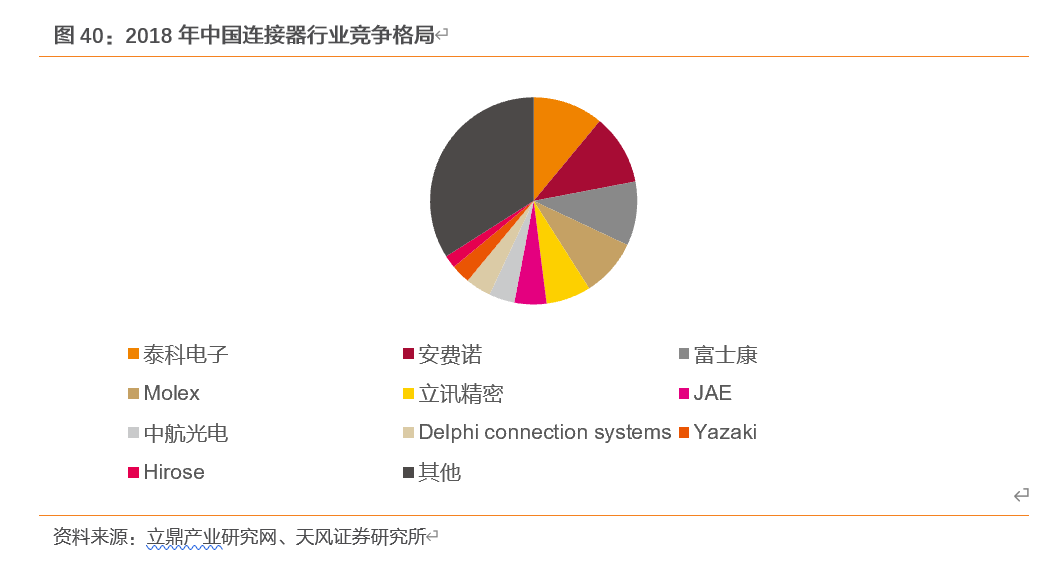
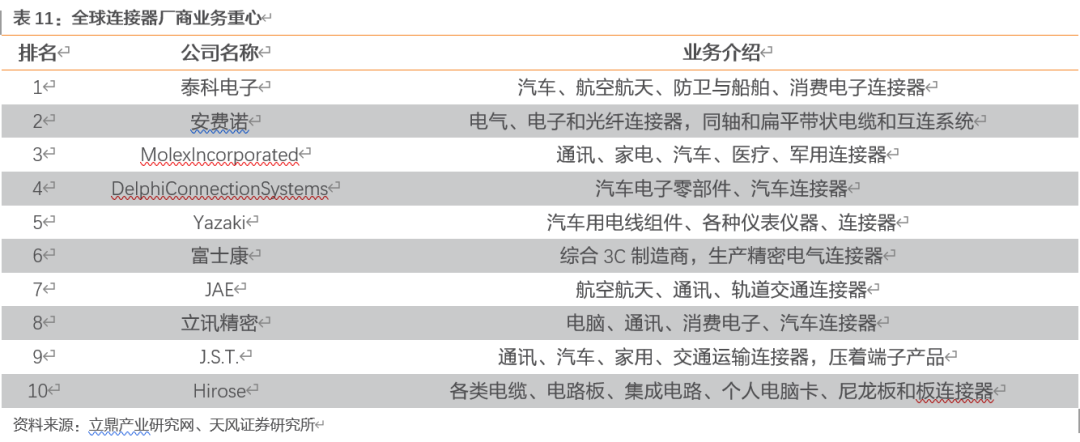
目前国内参与连接器竞争的企业主要包括四类:一类是以泰科电子(TEConnectivity)、安费诺(Amphenol)、莫仕(Molex)等为代表的大型跨国连接器厂商,技术水平较高、产品性能优越,具备较强竞争力。第二类是以矢崎(Yazaki)、日本压着端子(JST)、广濑电机(Hirose)等为代表的日本企业和以鸿海精密为代表的台资企业,其连接器产品在电脑及外设等个别应用领域的市场优势较为明显。第三类是以立讯精密、、公司为代表的研发技术水平、产销规模等方面居于国内领先的少数自主品牌厂商,其连接器产品在智能手机、平板电脑、家用电器等细分下游产品的应用领域占据一定竞争优势。最后是数量众多、技术水平相对落后、规模较小的连接器生产企业,产品同质化现象较为严重,也面临着较为激烈的市场竞争。

在国家产业政策积极引领和下游应用快速发展、国际产业转移的推动下,中国连接器行业近年来整体技术水平取得了明显进步,但与国际大型企业相比仍存在一定差距,主要表现为:领先企业的技术专长领域较为局限,限制了企业的业务开拓能力,难以和国际巨头进行全方位竞争;多数企业主动创新能力较差,仍处在追赶国际领先技术的过程中;关键制造设备上缺乏自主创新能力,进口依赖度较高。这些差距对国内连接器行业向高端技术、高端产品全面发展构成了一定挑战。
4. 盈利预测与投资建议
目前受益于下游消费电子领域的景气度上行,对连接器件需求量加大,看好公司连接器业务业绩持续上升,占据较大市场份额。同时公司通过外延方式布局软板业务,看好公司品类扩张,软板业务持续放量业绩兑现,找到新的利润增长点。
核心假设:
1、新技术和新产品研发进度符合预期;
2、5G发展符合预期;
3、下游应用需求不出现大幅波动
我们预计公司2020-2022年归母净利润分别为2.70/3.60和4.68亿元。
由于公司主业为连接器行业,选取同行可比对象,中航光电、立讯精密,2021年平均PE为43.64倍,基于谨慎原则,给予公司40倍PE,对应2021年利润3.60亿,目标市值144亿元,目标价51.28元,给予“买入”评级。

5. 风险提示
5G发展不及预期:对企业的新产品的推广产生影响,导致研发费用增长,影响新产品的市场布局。公司储备的新产品是公司全面对接5G的重要砝码,5G发展如果未达预期,将对新产品的营收产生一定影响,新老产品的切换期也将一定程度延长。
受疫情影响,下游应用需求不及预期:2020年初在全球范围内快速蔓延的新型冠状病毒肺炎疫情,对全球经济造成严重冲击,全球供应链体系受到严重挑战,严重限制了物流、人员往来及商业活动的开展。如果新型冠状病毒肺炎继续扩散,会对公司业务产生不利影响,其影响程度将取决于疫情蔓延程度、疫情防控情况、持续时间以及恢复情况等。若下游景气度不及预期,将影响公司产能利用率,影响公司业绩增长。
研发进度不及预期:下游行业需求持续升级,如果在技术研发及新产品开发方面不能持续保持高水平,公司经营风险将会显著增加。公司目前的市场地位和竞争优势与公司拥有的自主知识产权及其对应的核心技术密切相关。以智能移动终端为代表的下游应用领域相关产品更新换代的速度较快,决定了公司客户对连接器产品的需求也不断更新升级,因此公司需要具备快速响应下游行业需求的新产品开发能力和销售服务能力,这要求公司在技术研发上持续投入并保持高水平。
注:文中报告节选自研究所已公开发布研究报告,具体报告内容及相关风险提示等详见完整版报告。
证券研究报告《:创新驱动公司成长,多元产品放量贡献营收》
对外发布时间 2020年2月2日
报告发布机构 天风证券股份有限公司
本报告分析师:
潘暕 SAC执业证书编号:S1110517070005
许俊峰 SAC执业证书编号:S1110520110003
